MIT 6.S081 2020 xv6 labs
20 年的 xv6 实验和 21 年主要有两个不同:
- 20 年多了一个
sbrk的 Lazy allocation; - 20 年的页表实验和 21 年有很大不同,难度较高;
代码:https://github.com/CH3CHOHCH3/xv6-labs-2020
问答题直接看对应的 answers-lab.txt 即可。
Lab3 Page tables
xv6 的用户态和内核态使用不同的页表:每个进程有自己的进程页表,内核使用一个全局内核页表。当内核想要从进程地址空间获取参数,或是向其中写入内容时,xv6 采用的做法是利用内核数据的恒等映射,软件模拟 MMU 查询进程虚拟地址对应的物理地址。这个实验的主要目标是为每个进程实现自己的内核页表,切换进程时顺带切换内核页表,然后内核就能直接访问用户地址空间而不需要多次查询页表。
注意,内核态和用户态之所以能共用页表,是因为 xv6 默认每个进程的虚拟地址空间从 0 开始依次是代码段、数据段、栈保护页、栈、堆,在虚拟地址空间最高处映射了 TRAMPOLINE 和 TRAPFRAME 两个页;而内核页表原本映射的最低处是 CLINT 对应的 0x2000000,但这个地址用来在机器态处理时钟,所以用户的内核页表完全没必要映射,最低地址变为 PLIC,最高地址则是 TRAMPOLINE 和每个进程的内核栈及保护页(内核不需要映射 TRAMPFRAME 页,直接访问 p->trapframe 即可)。
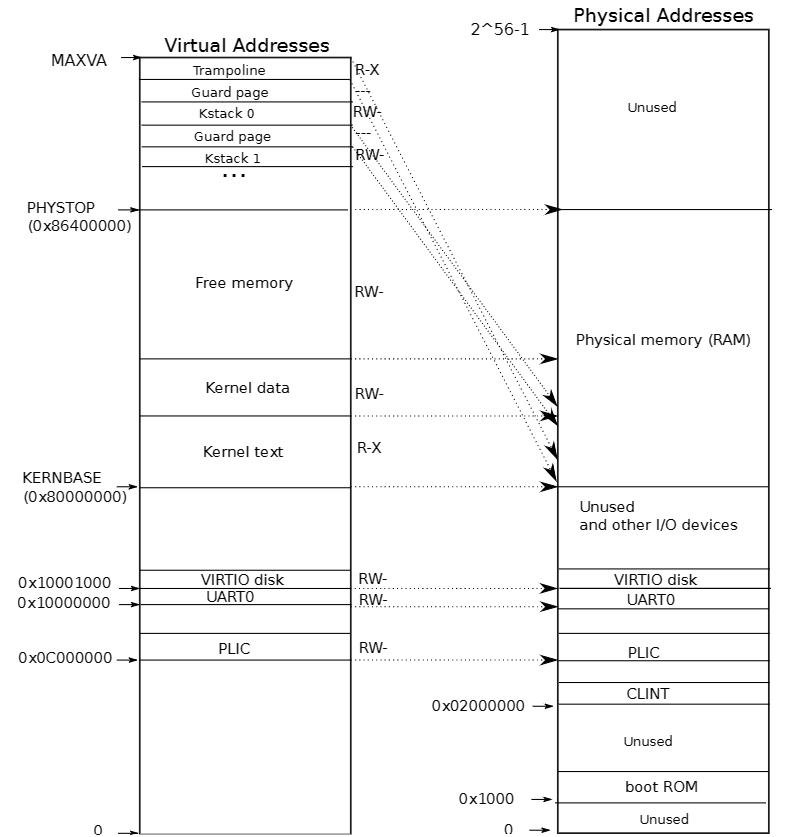
也就是说,为了满足用户态和内核态共用页表,用户进程占用的最高地址空间不能超过 PLIC,而进程需要用到的 TRAMPFRAME 则保存在用户页表中(其实可以处理一下 TRAPFRAME 和进程内核栈的冲突,每个进程的内核和用户态统一用一张页表,在陷入时甚至不需要切换页表)。
Print a page table
这个任务和 21 年任务二没有任何区别。
A kernel page table per process
这个任务即为每个进程实现自己的内核页表,并处理好页表的切换和释放等细节。
指导书的意见是给每个进程创建一份页表,然后参考 kvminit 把该映射的内容映射进去。事实上,我们知道每个进程用户态虚拟地址空间最多能用的大小只有 0xC000000,而三级页表中一个一级页表项能对应的地址空间大小为 0x40000000,所以我们只需要在 allocproc 中用一个页复制全局内核页表的 1-511 项,然后单独映射第 0 项(代码实现)
而在 freeproc 中释放进程内核页表时,也只需要递归释放其第一项对应的页表项(物理页会被 proc_freepagetable 回收)。
最后在 scheduler 中切换进程内核页表即可。
Simplify copyin/copyinstr
这个任务完成对 copyin 和 copyinstr 的最终简化。实验框架已经写好了这两个函数,只需要把原本的函数替换。我们需要做的是把进程的用户虚拟地址空间映射到进程自己的内核页表。这里面有两个问题:
- 怎么映射:代码胜千言;
- 何时映射:进程最初创建的时候要完成映射,这里主要是
fork和userinit两个函数;进程修改页表项的时候,要修改映射,这里主要是sbrk和exec,具体映射时机和参数可以参考同一个 commit;
解决这两个问题,也就完成了本次实验。
Lab5 Lazy allocation
本实验要求为 sbrk 系统调用增加的页面实现 Lazy 分配。众所周知,sbrk 会增加进程堆的大小,内核为其分配物理页并完成内存映射;而所谓 lazy 分配即只增加 p->sz 的大小,而物理页的分配延迟到缺页中断处理程序进行。实现这个功能比想象中更复杂一些,因为“本应存在的虚拟内存”这一概念会在很多地方带来问题。
首先,我们修改 sys_sbrk 的实现:
- 对于正参数,只增加
p->sz并返回; - 对于负参数,参考
growproc,直接调用uvmdealloc;
接下来,在 usertrap 中增加缺页的中断处理代码。这里需要判断是否是 lazy 分配导致的缺页,具体来说,发生缺页的虚拟地址应当满足:
- 不超过
p->sz; - 不低于进程的用户栈;
可以参考 xv6 book 中关于进程虚拟内存分布的图:
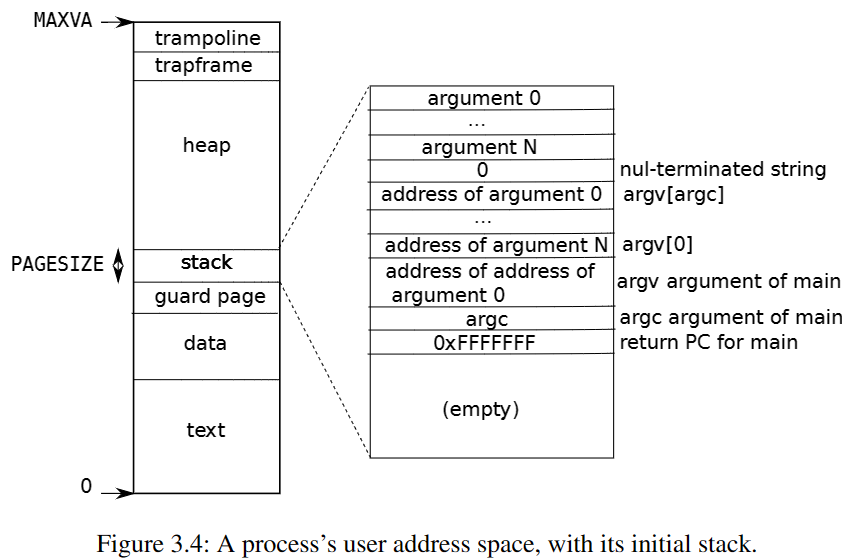
除此之外,未映射的虚拟地址会导致 uvmcopy 和 uvmunmap 报错,这里可以直接把 panic 改为 continue;而且内核通过 copyin/copyout 访问未分配的虚拟地址也会报错,这两个函数依然需要判断是否是 lazy 分配导致的缺页并为之分配物理页、完成映射。